布谷鸟哈希学习笔记。
由生日悖论可知,往大小为 m m m O ( m ) O\left(\sqrt{m}\right) O ( m ) m m m m / 2 m/2 m / 2 m / 2 m/2 m / 2
在布谷鸟哈希中,每个元素 v v v h 1 ( v ) , h 2 ( v ) h_1(v),h_2(v) h 1 ( v ) , h 2 ( v ) v v v h 1 ( v ) , h 2 ( v ) h_1(v),h_2(v) h 1 ( v ) , h 2 ( v ) v v v
但不是在所有的时候都可以安放好的,如果替换关系成环(即一开始插入的值又在同一个地方被踢出去),那么将所有元素都安放好是不可能的。这时候我们选取新的哈希函数 h 1 ′ , h 2 ′ h_1',h_2' h 1 ′ , h 2 ′ K K K K K K
布谷鸟哈希的删除和查找操作比较简单,只需要查询对应两个哈希值位置有无值即可。
小知识: 此算法名称来源于布谷鸟的行为:新出生的布谷鸟会本能地将巢穴里的其他蛋踢开,推出鸟巢,以确保自己在鸟巢里可以独享宠爱。插入时的「踢出」行为与布谷鸟的行为相似。当然被踢出的值比被踢开的蛋待遇要好得多,至少它可以「活下来」。
设 U \mathcal U U T T T 1 , 2 , … , ∣ T ∣ 1,2,\ldots,|T| 1 , 2 , … , ∣ T ∣ h 1 , h 2 h_1,h_2 h 1 , h 2
查找与删除操作的伪代码非常简单:
看代码就可以显然的看出查找与删除操作的时间复杂度都是 O ( 1 ) O(1) O ( 1 )
插入操作最为特殊:
接下来我们重点分析插入操作的时间复杂度。
因为插入操作的复杂度依赖于哈希函数,所以我们要对哈希函数做一些限制(不然可以设计极端好或者极端差的哈希函数从而使得算法的复杂度失去意义)。
定义(k k k 我们称一个哈希函数(哈希函数指的是这样的映射:h : U → [ T ] h:\mathcal U\to [T] h : U → [ T ] H \mathcal H H k k k k k k x 1 , x 2 , … , x k ∈ U x_1,x_2,\ldots,x_k\in \mathcal U x 1 , x 2 , … , x k ∈ U k k k y 1 , y 2 … , y k ∈ [ T ] y_1,y_2\ldots,y_k\in [T] y 1 , y 2 … , y k ∈ [ T ]
Pr h ∈ H [ h ( x 1 ) = y 1 ∧ h ( x 2 ) = y 2 ∧ … ∧ h ( x k ) = y k ] ≤ 1 ∣ T ∣ k \Pr_{h\in \mathcal H}[h(x_1)=y_1\wedge h(x_2)=y_2\wedge \ldots\wedge h(x_k)=y_k]\le \dfrac 1{|T|^k}
h ∈ H Pr [ h ( x 1 ) = y 1 ∧ h ( x 2 ) = y 2 ∧ … ∧ h ( x k ) = y k ] ≤ ∣ T ∣ k 1
在下面的分析中我们都假设我们选取的哈希函数是 2 K 2K 2 K h 1 , h 2 h_1,h_2 h 1 , h 2
设哈希表中目前填入了 n n n 装载参数 为:
α = n ∣ T ∣ \alpha=\dfrac{n}{|T|}
α = ∣ T ∣ n
我们在进行整个过程的时候,我们要一直保持:
α < 1 2 + δ \alpha< \dfrac 1{2+\delta}
α < 2 + δ 1
即一直保持:
∣ T ∣ > ( 2 + δ ) n |T|> (2+\delta)n
∣ T ∣ > ( 2 + δ ) n
如果插入了一个元素后上述条件不满足了,我们就将哈希表的大小扩大为原来的两倍,重新选取哈希函数,然后把原来在表里的元素重新插入进去,这个操作被称为表扩容 。
往哈希表里插入一个元素 x x x 5 5 5 14 14 1 4 x x x 迭代序列 ,并设这个序列具体为:x 1 = x , x 2 , x 3 , … x_1=x,x_2,x_3,\ldots x 1 = x , x 2 , x 3 , … 2 K 2K 2 K K K K
如果先不管序列长度的限制,让其一直迭代下去,我们可以把序列分为三类:
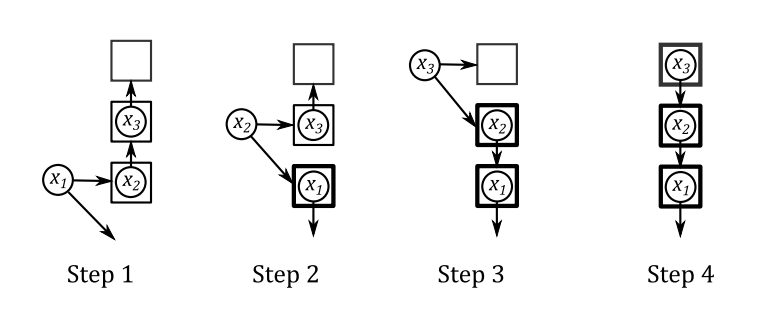
序列中的每个值都不同,这也蕴含着迭代会终止。
序列中存在相同的元素,但是迭代会终止。
序列中存在相同的元素,并且迭代不会终止。
第一种情况最好分析,直接放一张图解释。
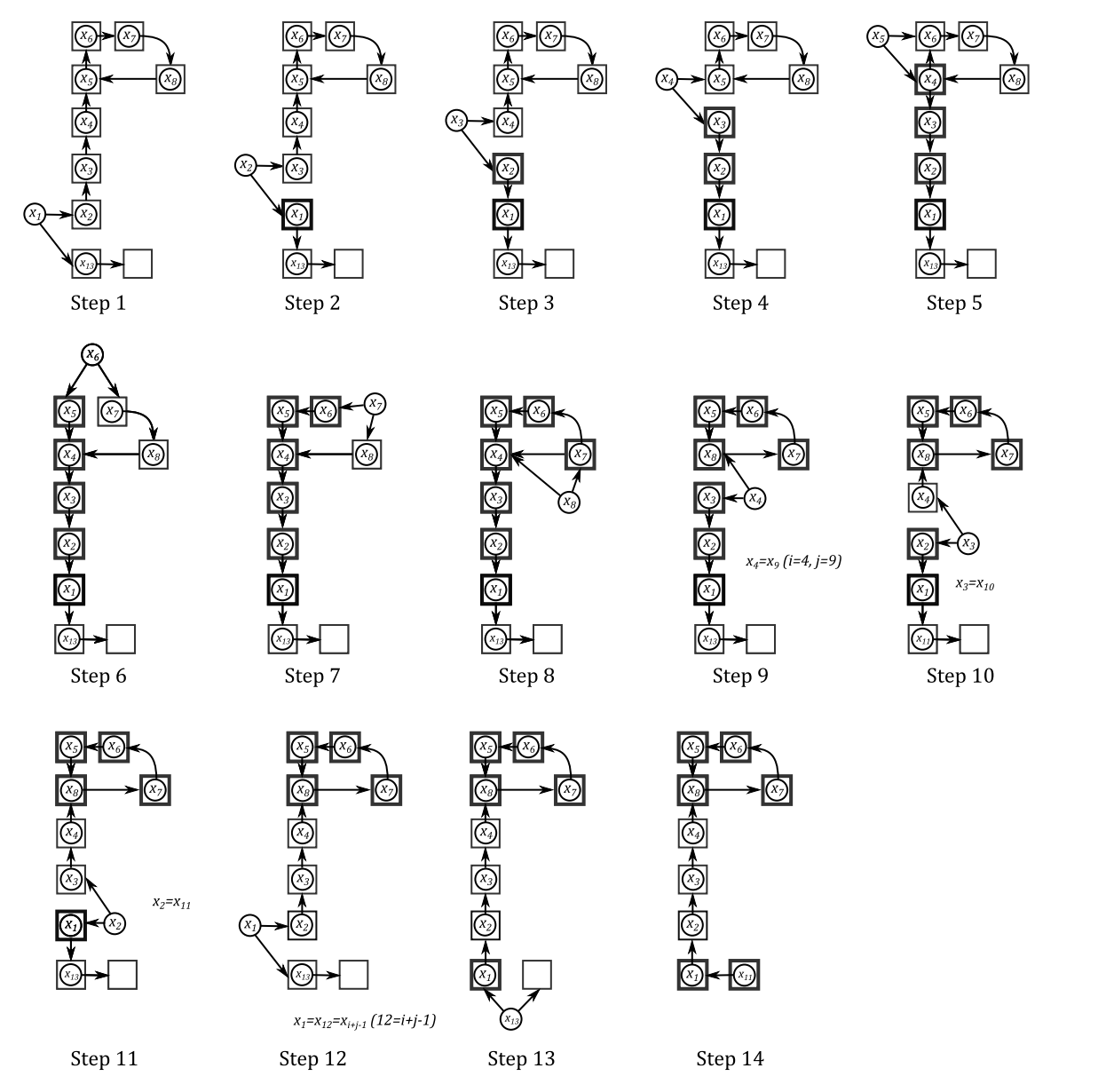
第二种情况,我们假设序列中相同的两个元素是 x i , x j ( i < j ) x_i,x_j\,(i<j) x i , x j ( i < j ) ( i , j ) (i,j) ( i , j ) x j + 1 = x i − 1 , x j + 2 = x i − 2 , … , x j + i − 1 = x 1 = x x_{j+1}=x_{i-1},x_{j+2}=x_{i-2},\ldots,x_{j+i-1}=x_1=x x j + 1 = x i − 1 , x j + 2 = x i − 2 , … , x j + i − 1 = x 1 = x l l l
第三种情况与第二种类似,但是不同就是再度回到 x x x x x x x x x
我们称一个序列 x 1 = x , x 2 , … , x l x_1=x,x_2,\ldots,x_l x 1 = x , x 2 , … , x l 坏 的,当且仅当这个序列已经开始循环了,否则则称它是好 的。那么有如下重要引理:
引理 1 1 1 插入迭代到第 l l l x 1 = x , x 2 , … , x l x_1=x,x_2,\ldots,x_l x 1 = x , x 2 , … , x l p ≥ l / 3 p\ge l/3 p ≥ l / 3 x q , x q + 1 , … , x q + p − 1 x_q,x_{q+1},\ldots,x_{q+p-1} x q , x q + 1 , … , x q + p − 1 x q = x 1 = x x_q=x_1=x x q = x 1 = x
证明: 如果 x 1 , … , x l x_1,\ldots,x_l x 1 , … , x l
如果 x i = x j ( i < j ) x_i=x_j\,(i<j) x i = x j ( i < j ) ( i , j ) (i,j) ( i , j )
若 l < i + j l<i+j l < i + j x 1 = x , … , x j − 1 x_1=x,\ldots,x_{j-1} x 1 = x , … , x j − 1 x 1 = x x_1=x x 1 = x j − 1 ≥ ( i + j − 1 ) / 2 ≥ l / 2 > l / 3 j-1\ge (i+j-1)/2\ge l/2> l/3 j − 1 ≥ ( i + j − 1 ) / 2 ≥ l / 2 > l / 3
而若 l ≥ i + j l\ge i+j l ≥ i + j x 1 , … , x j − 1 x_1,\ldots,x_{j-1} x 1 , … , x j − 1 x i + j − 1 , … , x l x_{i+j-1},\ldots,x_l x i + j − 1 , … , x l x 1 = x i + j − 1 = x x_1=x_{i+j-1}=x x 1 = x i + j − 1 = x l / 3 l/3 l / 3
两个子序列长度分别为 j − 1 , l − i − j + 2 j-1,l-i-j+2 j − 1 , l − i − j + 2 l = ( j − 1 ) + ( i − 1 ) + ( l − i − j + 2 ) l=(j-1)+(i-1)+(l-i-j+2) l = ( j − 1 ) + ( i − 1 ) + ( l − i − j + 2 ) j − 1 > i − 1 j-1>i-1 j − 1 > i − 1 j − 1 > l − i − j + 2 j-1>l-i-j+2 j − 1 > l − i − j + 2 3 ( j − 1 ) > l 3(j-1)>l 3 ( j − 1 ) > l j − 1 ≤ l − i − j + 2 j-1\le l-i-j+2 j − 1 ≤ l − i − j + 2 3 ( l − i − j + 2 ) ≤ l 3(l-i-j+2)\le l 3 ( l − i − j + 2 ) ≤ l l / 3 l/3 l / 3
得证。□ \Box □
有了这样一个引理的准备,我们可以着手开始分析插入操作的期望时间复杂度。先写出期望时间复杂度的表达式:
E n ( Insert ) = O ( ∑ i = 1 2 K Pr [ ∣ x ∣ = i ] ⋅ i ) + Pr n [ Insert Fail ] ⋅ ( E n ( ReHash ) + E n ( Insert ) ) , E n ( ReHash ) = ∑ i = 0 n − 1 E i ( Insert ) ≤ n ⋅ E n ( Insert ) \mathbb E_n(\text{Insert})=O\left(\sum_{i=1}^{2K}\Pr[|x|=i]\cdot i \right)+{\Pr}_n[\text{Insert Fail}]\cdot (\mathbb E_n(\text{ReHash})+\mathbb E_n(\text{Insert})),\\
\mathbb E_n(\text{ReHash})=\sum_{i=0}^{n-1}\mathbb E_i(\text{Insert})\le n\cdot \mathbb E_n(\text{Insert})
E n ( Insert ) = O ( i = 1 ∑ 2 K Pr [ ∣ x ∣ = i ] ⋅ i ) + Pr n [ Insert Fail ] ⋅ ( E n ( ReHash ) + E n ( Insert ) ) , E n ( ReHash ) = i = 0 ∑ n − 1 E i ( Insert ) ≤ n ⋅ E n ( Insert )
其中 n n n E n ( Insert ) , E n ( ReHash ) , Pr n [ Insert Fail ] \mathbb E_n(\text{Insert}),\mathbb E_n(\text{ReHash}),{\Pr}_n[\text{Insert Fail}] E n ( Insert ) , E n ( ReHash ) , Pr n [ Insert Fail ] n n n 5 5 5 ∣ x ∣ |x| ∣ x ∣ x x x
显然 E i ( Insert ) \mathbb E_i(\text{Insert}) E i ( Insert )
可以发现把第二个式子直接代入第一个式子,就变成了只关于 E n ( Insert ) \mathbb E_n(\text{Insert}) E n ( Insert ) O O O Pr n [ Insert Fail ] {\Pr}_n[\text{Insert Fail}] Pr n [ Insert Fail ]
我们先来分析大 O O O
∑ i = 1 2 K Pr [ ∣ x ∣ = i ] ⋅ i = ∑ i = 1 2 K Pr [ ∣ x ∣ ≥ i ] \sum_{i=1}^{2K}\Pr[|x|=i]\cdot i=\sum_{i=1}^{2K}\Pr[|x|\ge i]
i = 1 ∑ 2 K Pr [ ∣ x ∣ = i ] ⋅ i = i = 1 ∑ 2 K Pr [ ∣ x ∣ ≥ i ]
所以我们去考虑分析 Pr [ ∣ x ∣ ≥ i ] \Pr[|x|\ge i] Pr [ ∣ x ∣ ≥ i ] V = V= V = ∣ x ∣ ≥ i |x|\ge i ∣ x ∣ ≥ i X = X= X = x 1 , … , x i x_1,\ldots,x_i x 1 , … , x i Y = Y= Y = x 1 , … , x i x_1,\ldots,x_i x 1 , … , x i
Pr [ V ] = Pr [ V ∧ X ] + Pr [ V ∧ Y ] \Pr[V]=\Pr[V\wedge X]+\Pr[V\wedge Y]
Pr [ V ] = Pr [ V ∧ X ] + Pr [ V ∧ Y ]
又注意到 V ∩ X = X , V ∩ Y = Y V\cap X=X,V\cap Y=Y V ∩ X = X , V ∩ Y = Y
Pr [ V ] = Pr [ X ] + Pr [ Y ] \Pr[V]=\Pr[X]+\Pr[Y]
Pr [ V ] = Pr [ X ] + Pr [ Y ]
接下来我们分别分析 Pr [ X ] \Pr[X] Pr [ X ] Pr [ Y ] \Pr[Y] Pr [ Y ]
我们先来分析 Pr [ X ] \Pr[X] Pr [ X ] 1 1 1 i / 3 i/3 i / 3 b 1 = x , b 2 , … , b i / 3 b_1=x,b_2,\ldots,b_{i/3} b 1 = x , b 2 , … , b i / 3
如果 b 1 b_1 b 1 x x x
h 1 ( b 1 ) = h 1 ( b 2 ) , h 2 ( b 2 ) = h 2 ( b 3 ) , h 1 ( b 3 ) = h 1 ( b 4 ) , … (1) h_1(b_1)=h_1(b_2),h_2(b_2)=h_2(b_3),h_1(b_3)=h_1(b_4),
\ldots \tag{1}
h 1 ( b 1 ) = h 1 ( b 2 ) , h 2 ( b 2 ) = h 2 ( b 3 ) , h 1 ( b 3 ) = h 1 ( b 4 ) , … ( 1 )
而若 b 1 b_1 b 1 x x x
h 2 ( b 1 ) = h 2 ( b 2 ) , h 1 ( b 2 ) = h 1 ( b 3 ) , h 2 ( b 3 ) = h 2 ( b 4 ) , … (2) h_2(b_1)=h_2(b_2),h_1(b_2)=h_1(b_3),h_2(b_3)=h_2(b_4),
\ldots \tag{2}
h 2 ( b 1 ) = h 2 ( b 2 ) , h 1 ( b 2 ) = h 1 ( b 3 ) , h 2 ( b 3 ) = h 2 ( b 4 ) , … ( 2 )
b b b
1 ⋅ ( n − 1 ) ⋯ ( n − i / 3 + 1 ) ≤ n i / 3 − 1 1\cdot (n-1)\cdots (n-i/3+1)\le n^{i/3-1}
1 ⋅ ( n − 1 ) ⋯ ( n − i / 3 + 1 ) ≤ n i / 3 − 1
选定了 b b b ( 1 ) (1) ( 1 ) h 1 , h 2 h_1,h_2 h 1 , h 2 2 K 2K 2 K h 1 , h 2 h_1,h_2 h 1 , h 2 i / 3 i/3 i / 3 h 1 h_1 h 1 [ 1 , ∣ T ∣ / 2 ] [1,|T|/2] [ 1 , ∣ T ∣ / 2 ] h 2 h_2 h 2 [ ∣ T ∣ / 2 + 1 , ∣ T ∣ ] [|T|/2+1,|T|] [ ∣ T ∣ / 2 + 1 , ∣ T ∣ ]
Pr [ h 1 ( b 1 ) = h 1 ( b 2 ) ∧ h 2 ( b 2 ) = h 2 ( b 3 ) ∧ … ] = ∑ y 1 , y 3 , y 3 , … ∈ [ 1 , ∣ T ∣ / 2 ] Pr [ h 1 ( b 1 ) = h 1 ( b 2 ) = y 1 ∧ h 1 ( b 3 ) = h 1 ( b 4 ) = y 3 ∧ … ] ⋅ ∑ y 2 , y 4 , y 6 , … ∈ [ ∣ T ∣ / 2 + 1 , ∣ T ∣ ] Pr [ h 2 ( b 2 ) = h 2 ( b 3 ) = y 2 ∧ h 2 ( b 4 ) = h 2 ( b 5 ) = y 4 ∧ … ] ≤ ( ∣ T ∣ / 2 ) i / 3 − 1 ( ∣ T ∣ / 2 ) i / 3 − 1 ( ∣ T ∣ / 2 ) i / 3 − 1 = 1 ( ∣ T ∣ / 2 ) i / 3 − 1 \Pr[h_1(b_1)=h_1(b_2)\wedge h_2(b_2)=h_2(b_3) \wedge
\ldots]\\
=\sum_{y_1,y_3,y_3,\ldots\in[1,|T|/2]}\Pr[h_1(b_1)=h_1(b_2)=y_1\wedge h_1(b_3)=h_1(b_4)=y_3 \wedge
\ldots]\cdot \\
\sum_{y_2,y_4,y_6,\ldots\in[|T|/2+1,|T|]}\Pr[h_2(b_2)=h_2(b_3)=y_2\wedge h_2(b_4)=h_2(b_5)=y_4 \wedge
\ldots] \\
\le \dfrac{(|T|/2)^{i/3-1}}{(|T|/2)^{i/3-1}(|T|/2)^{i/3-1}}=\dfrac 1{(|T|/2)^{i/3-1}}
Pr [ h 1 ( b 1 ) = h 1 ( b 2 ) ∧ h 2 ( b 2 ) = h 2 ( b 3 ) ∧ … ] = y 1 , y 3 , y 3 , … ∈ [ 1 , ∣ T ∣ / 2 ] ∑ Pr [ h 1 ( b 1 ) = h 1 ( b 2 ) = y 1 ∧ h 1 ( b 3 ) = h 1 ( b 4 ) = y 3 ∧ … ] ⋅ y 2 , y 4 , y 6 , … ∈ [ ∣ T ∣ / 2 + 1 , ∣ T ∣ ] ∑ Pr [ h 2 ( b 2 ) = h 2 ( b 3 ) = y 2 ∧ h 2 ( b 4 ) = h 2 ( b 5 ) = y 4 ∧ … ] ≤ ( ∣ T ∣ / 2 ) i / 3 − 1 ( ∣ T ∣ / 2 ) i / 3 − 1 ( ∣ T ∣ / 2 ) i / 3 − 1 = ( ∣ T ∣ / 2 ) i / 3 − 1 1
同理 b b b ( 2 ) (2) ( 2 )
Pr [ X ] ≤ Pr [ 序列 x 中存在引理 1 描述的那样的连续子序列 ] ≤ 2 n i / 3 − 1 ( ∣ T ∣ / 2 ) i / 3 − 1 < 2 ( 1 + δ / 2 ) i / 3 − 1 \Pr[X]\le \Pr[\text{序列 }x\text{ 中存在引理 }1\text{ 描述的那样的连续子序列}] \\
\le \dfrac {2n^{i/3-1}}{(|T|/2)^{i/3-1}}< \dfrac 2{(1+\delta/2)^{i/3-1}}
Pr [ X ] ≤ Pr [ 序列 x 中存在引理 1 描述的那样的连续子序列 ] ≤ ( ∣ T ∣ / 2 ) i / 3 − 1 2 n i / 3 − 1 < ( 1 + δ / 2 ) i / 3 − 1 2
注意最后一步用了条件:∣ T ∣ > ( 2 + δ ) n |T|>(2+\delta)n ∣ T ∣ > ( 2 + δ ) n
设 v v v x 1 , … , x i x_1,\ldots,x_i x 1 , … , x i v v v
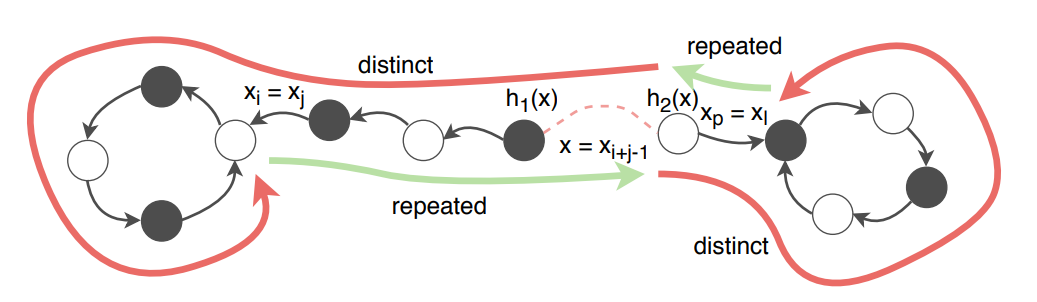
因为这个序列已经是坏的了,所以一定存在三个下标 j , k , w j,k,w j , k , w x i = x j = x w ( 1 ≤ j < k < j + k ≤ w ≤ i ) x_i=x_j=x_w\,(1\le j<k<j+k\le w\le i) x i = x j = x w ( 1 ≤ j < k < j + k ≤ w ≤ i )
为了方便分析,我们把前文中对第三种情况的解释图再搬下来。可以发现的是 ( j , k , w ) (j,k,w) ( j , k , w ) v v v ( j , k , w ) (j,k,w) ( j , k , w ) v v v ( v 3 ) ≤ v 3 \dbinom v 3\le v^3 ( 3 v ) ≤ v 3
对于这 v v v n v − 1 n^{v-1} n v − 1 x x x ( ∣ T ∣ / 2 ) v − 1 (|T|/2)^{v-1} ( ∣ T ∣ / 2 ) v − 1 x x x h 1 , h 2 h_1,h_2 h 1 , h 2 2 K 2K 2 K ( ∣ T ∣ / 2 ) − 2 v (|T|/2)^{-2v} ( ∣ T ∣ / 2 ) − 2 v v v v n v − 1 ( ∣ T ∣ / 2 ) v − 1 v 3 ( ∣ T ∣ / 2 ) − 2 v n^{v-1}(|T|/2)^{v-1}v^3(|T|/2)^{-2v} n v − 1 ( ∣ T ∣ / 2 ) v − 1 v 3 ( ∣ T ∣ / 2 ) − 2 v
那么我们可以写出 Pr [ Y ] \Pr[Y] Pr [ Y ]
Pr [ Y ] ≤ ∑ v = 3 i n v − 1 ( ∣ T ∣ / 2 ) v − 1 v 3 ( ∣ T ∣ / 2 ) − 2 v ≤ 2 ∣ T ∣ n ∑ v = 3 ∞ v 3 ( 2 n ∣ T ∣ ) v < 2 ∣ T ∣ n ∑ v = 3 ∞ v 3 ( 1 + δ / 2 ) − v = O ( 1 / n 2 ) \Pr[Y]\le \sum_{v=3}^i n^{v-1}(|T|/2)^{v-1}v^3(|T|/2)^{-2v}\\
\le \dfrac 2{|T|n}\sum_{v=3}^\infty v^3\left(\dfrac{2n}{|T|} \right)^v< \dfrac 2{|T|n}\sum_{v=3}^\infty v^3(1+\delta/2)^{-v}=O(1/n^2)
Pr [ Y ] ≤ v = 3 ∑ i n v − 1 ( ∣ T ∣ / 2 ) v − 1 v 3 ( ∣ T ∣ / 2 ) − 2 v ≤ ∣ T ∣ n 2 v = 3 ∑ ∞ v 3 ( ∣ T ∣ 2 n ) v < ∣ T ∣ n 2 v = 3 ∑ ∞ v 3 ( 1 + δ / 2 ) − v = O ( 1 / n 2 )
注意上述推导中用到了条件:∣ T ∣ > ( 2 + δ ) n , ∣ T ∣ = Ω ( n ) |T|> (2+\delta)n,|T|=\Omega(n) ∣ T ∣ > ( 2 + δ ) n , ∣ T ∣ = Ω ( n )
我们接下来去分析 Pr n [ Insert Fail ] {\Pr}_n[\text{Insert Fail}] Pr n [ Insert Fail ] 2 K 2K 2 K O ( 1 / n 2 ) O(1/n^2) O ( 1 / n 2 ) ( 1 + δ / 2 ) − 2 K / 3 + 1 (1+\delta/2)^{-2K/3+1} ( 1 + δ / 2 ) − 2 K / 3 + 1
我们令 K = ⌈ 3 log 1 + δ / 2 ∣ T ∣ ⌉ K=\lceil 3\log_{1+\delta/2}|T| \rceil K = ⌈ 3 log 1 + δ / 2 ∣ T ∣ ⌉
( 1 + δ / 2 ) − 2 ⌈ 3 log 1 + δ / 2 ∣ T ∣ ⌉ / 3 + 1 = O ( 1 / n 2 ) (1+\delta/2)^{-2\lceil 3\log_{1+\delta/2}|T| \rceil/3+1}=O(1/n^2)
( 1 + δ / 2 ) − 2 ⌈ 3 log 1 + δ / 2 ∣ T ∣ ⌉ / 3 + 1 = O ( 1 / n 2 )
所以 Pr n [ Insert Fail ] = O ( 1 / n 2 ) {\Pr}_n[\text{Insert Fail}]=O(1/n^2) Pr n [ Insert Fail ] = O ( 1 / n 2 )
首先有:
∑ i = 1 2 K Pr [ ∣ x ∣ ≥ i ] ≤ 1 + ∑ i = 2 2 K ( 2 ( 1 + δ / 2 ) i / 3 − 1 + O ( 1 / n 2 ) ) ≤ 1 + O ( 2 K n 2 ) + 2 ∑ i = 0 ∞ 1 ( 1 + δ / 2 ) i / 3 − 1 = O ( 1 ) \begin{aligned}
\sum_{i=1}^{2K}\Pr[|x|\ge i] & \le 1+\sum_{i=2}^{2K}\left(\dfrac 2{(1+\delta/2)^{i/3-1}} +O(1/n^2) \right) \\
& \le 1+O\left(\dfrac{2K}{n^2} \right)+2\sum_{i=0}^\infty \dfrac{1}{(1+\delta/2)^{i/3-1}} \\
& =O(1)
\end{aligned}
i = 1 ∑ 2 K Pr [ ∣ x ∣ ≥ i ] ≤ 1 + i = 2 ∑ 2 K ( ( 1 + δ / 2 ) i / 3 − 1 2 + O ( 1 / n 2 ) ) ≤ 1 + O ( n 2 2 K ) + 2 i = 0 ∑ ∞ ( 1 + δ / 2 ) i / 3 − 1 1 = O ( 1 )
注意在以上推导种我们已经令 K = ⌈ 3 log 1 + δ / 2 ∣ T ∣ ⌉ K=\lceil 3\log_{1+\delta/2}|T| \rceil K = ⌈ 3 log 1 + δ / 2 ∣ T ∣ ⌉
于是可以得到:
E n ( Insert ) ≤ O ( 1 ) + O ( 1 / n 2 ) ⋅ ( n + 1 ) ⋅ E n ( Insert ) ⇒ E n ( Insert ) = O ( 1 ) , E n ( ReHash ) = O ( n ) \mathbb E_n(\text{Insert})\le O(1)+O(1/n^2)\cdot (n+1)\cdot \mathbb E_n(\text{Insert})\\
\Rightarrow \mathbb E_n(\text{Insert})=O(1),\mathbb E_n(\text{ReHash})=O(n)
E n ( Insert ) ≤ O ( 1 ) + O ( 1 / n 2 ) ⋅ ( n + 1 ) ⋅ E n ( Insert ) ⇒ E n ( Insert ) = O ( 1 ) , E n ( ReHash ) = O ( n )
综上我们得出插入操作的期望时间复杂度是常数级别的。
假设已经插入了 n n n O ( log n ) O(\log n) O ( log n ) n , n / 2 , n / 4 , … n,n/2,n/4,\ldots n , n / 2 , n / 4 , … S S S O ( S ) O(S) O ( S ) n n n O ( n + n / 2 + … ) = O ( n ) O(n+n/2+\ldots)=O(n) O ( n + n / 2 + … ) = O ( n ) O ( 1 ) O(1) O ( 1 )
[1] Cuckoo Hashing and Cuckoo Filters. Noah Fleming, 2018. From Toronto University,https://www.cs.toronto.edu/~noahfleming/CuckooHashing.pdf .
[2] Cuckoo Hashing. From Standford University,https://web.stanford.edu/class/archive/cs/cs166/cs166.1146/lectures/13/Small13.pdf .
[3] An Overview of Cuckoo Hashing. Charles Chen. From Standford University,https://cs.stanford.edu/~rishig/courses/ref/l13a.pdf .